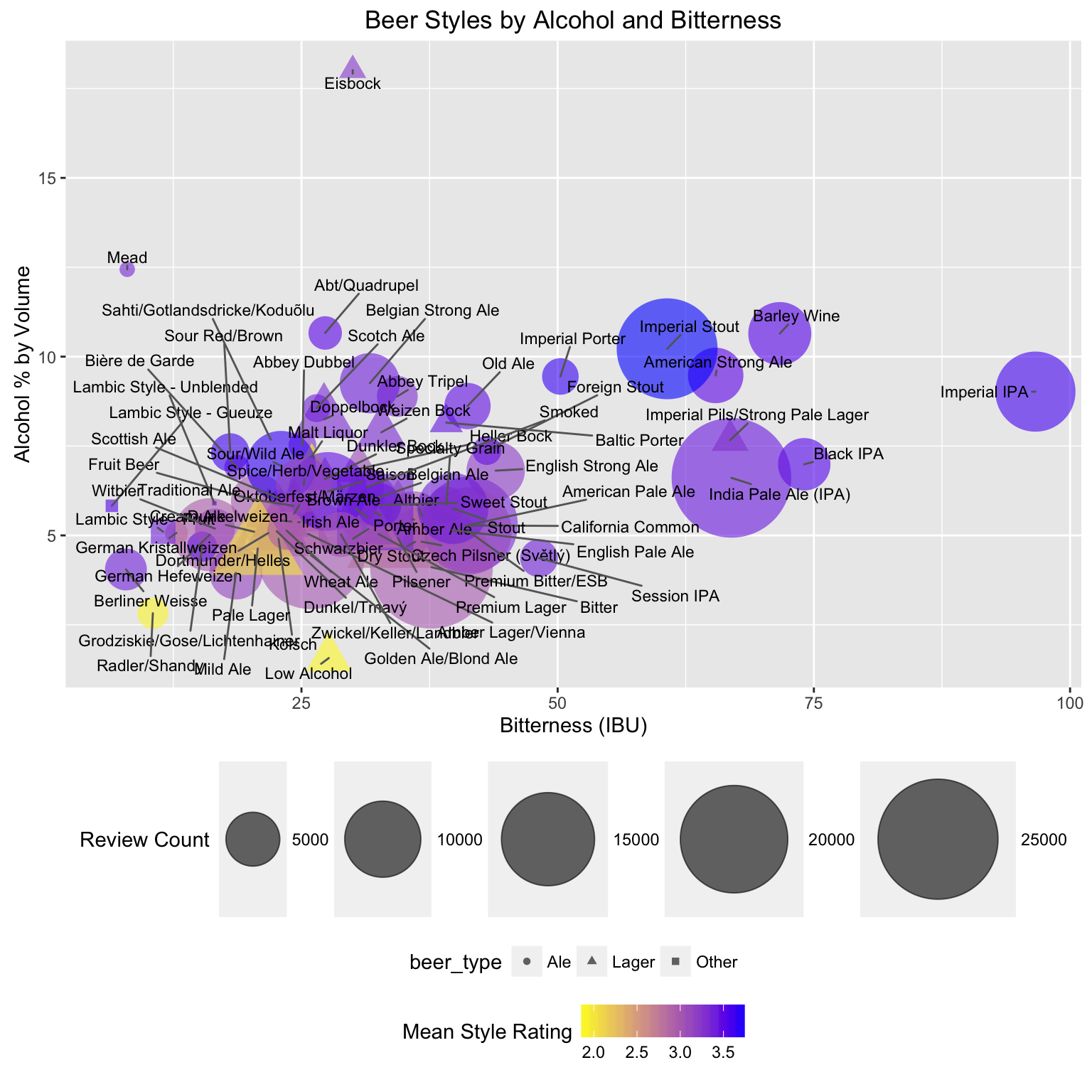
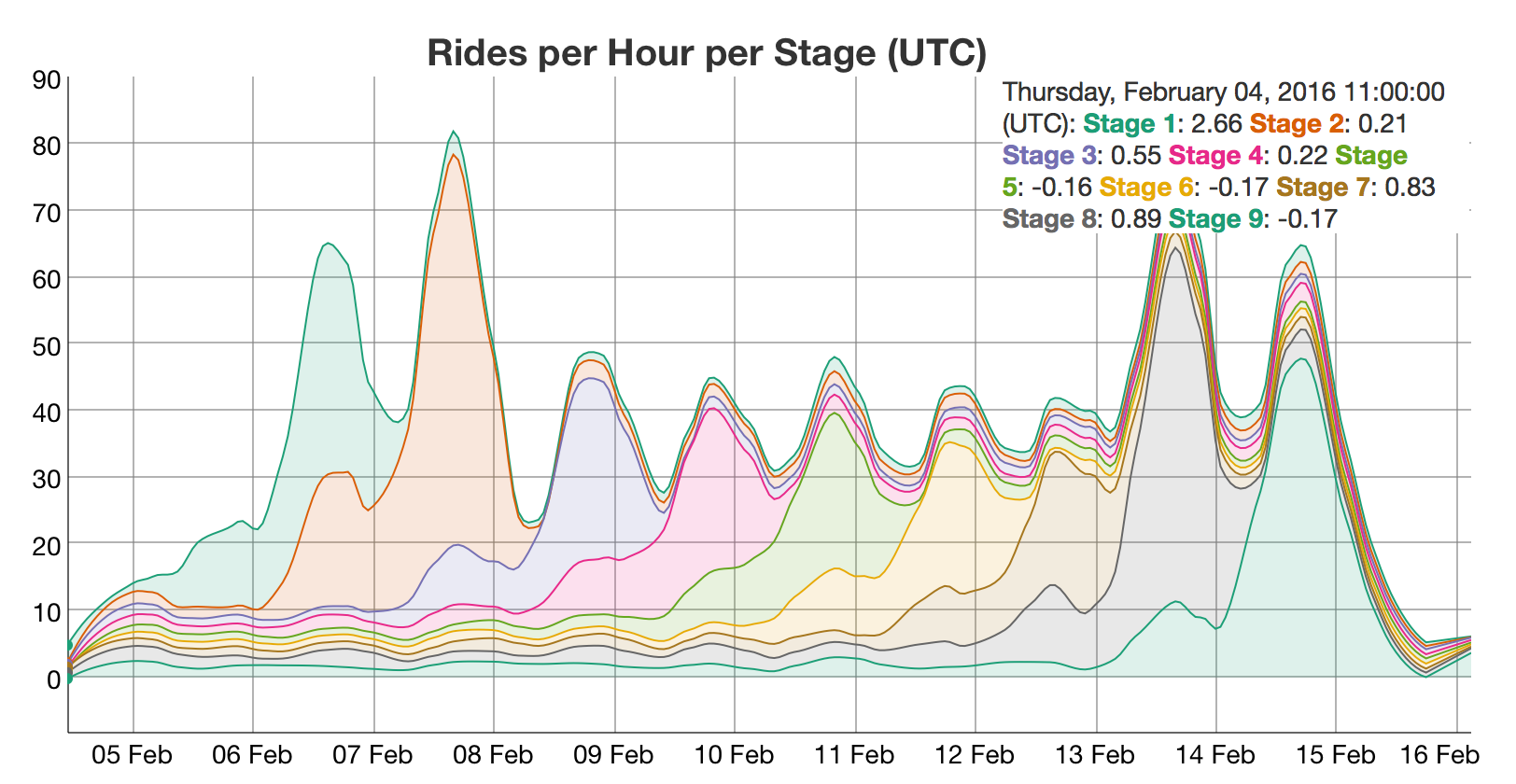
In this project, I dumped Open Street Map (OSM) data from the area around Ann Arbor and analyzed it for patterns. After doing basic statistical review of the data set, I started looking for patterns and outliers.
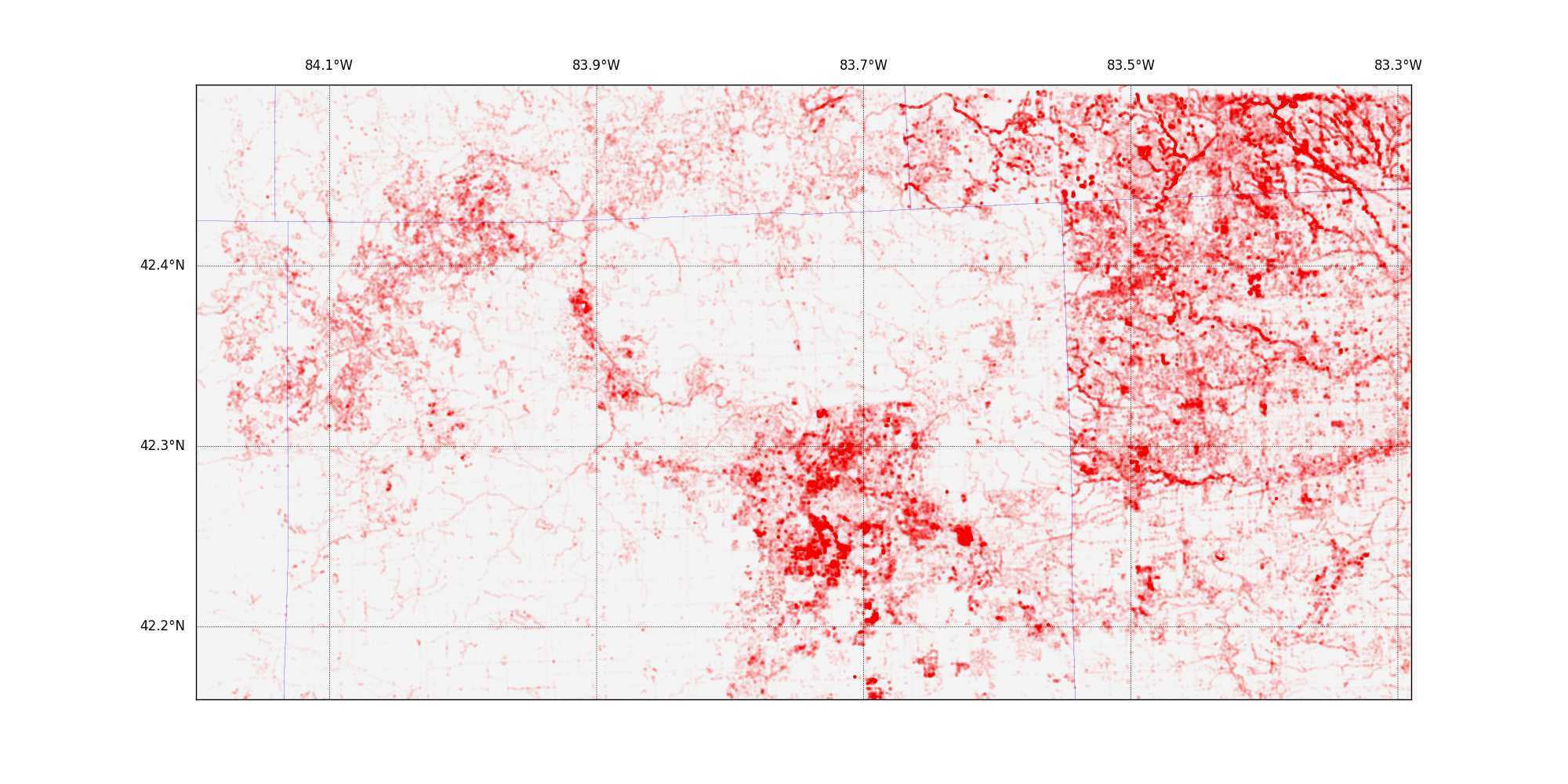
The data set , unfiltered and unlabeled, creates a compelling image that makes the difference in land-use policy between my county and the neighboring counties (part of suburban Detroit) obvious (click to embiggen):
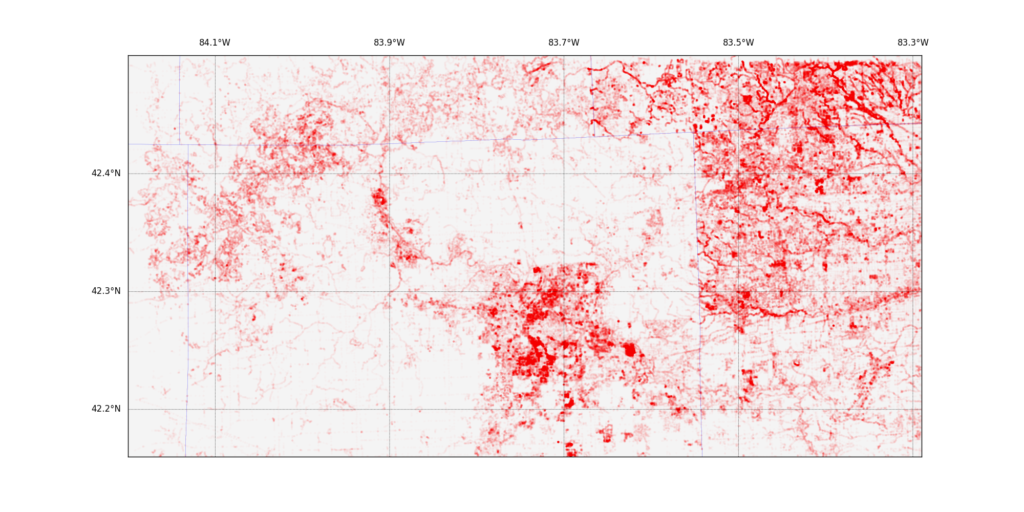
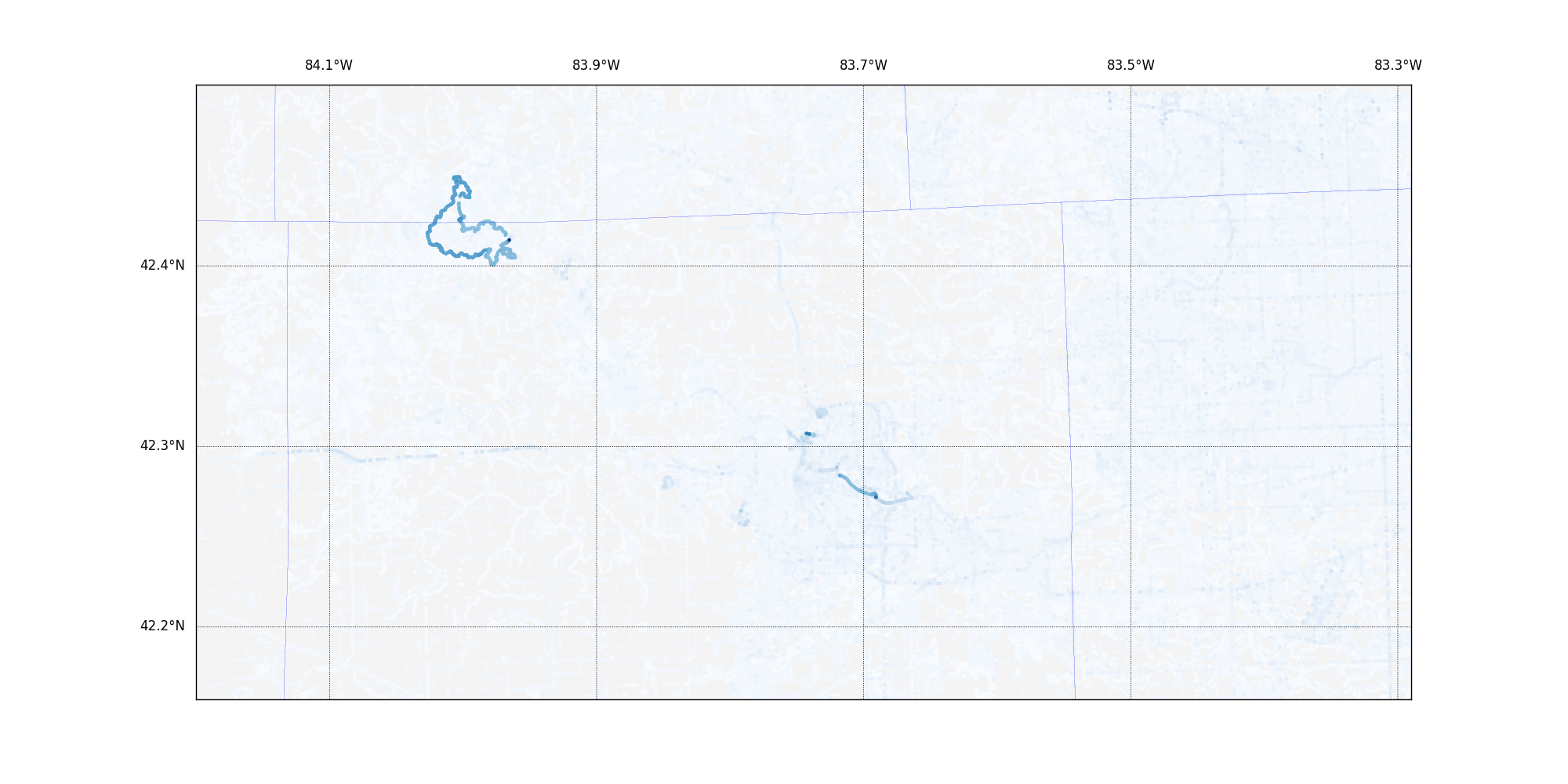
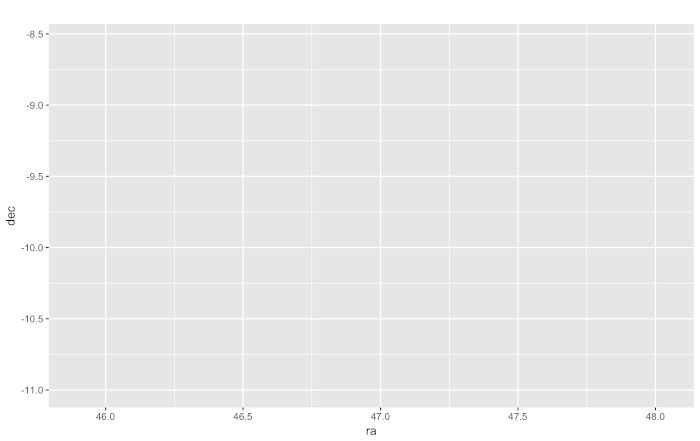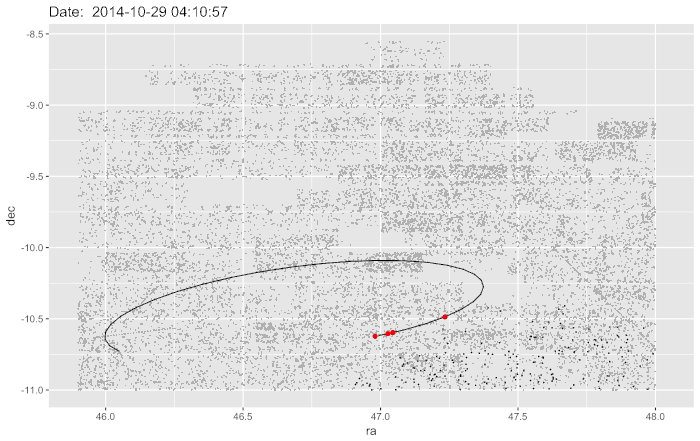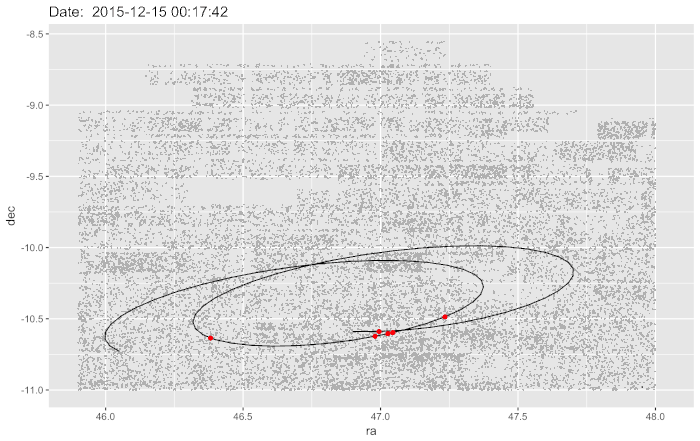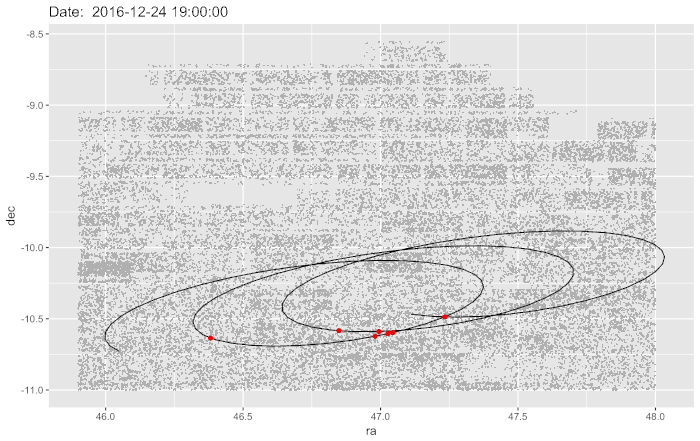
The red blob in the middle is the very densely populated part of Ann Arbor, surrounded by lots of rural land, right up to the borders with Wayne and Macomb counties. I did more analysis and decided to reshape the data to emphasize the number of edits any given pixel had had and discovered this:
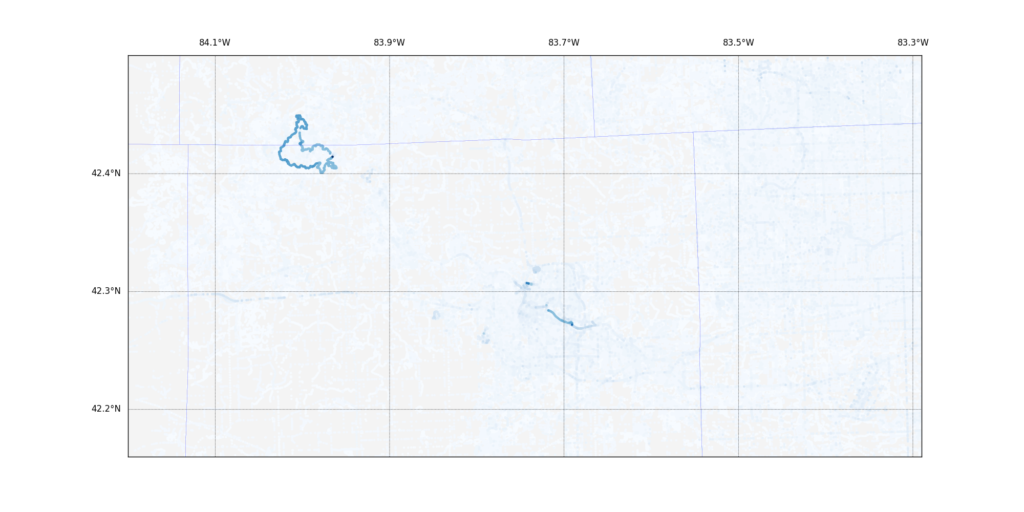
I had expected to see much more density in the heart of Ann Arbor as the busy city maps were continually updated, but instead, a 17-mile cycling trail popped out. The paper digs into this a little further.
http://kateweber.com/portfolio/ProjectReport.html


{kind=link}
{kind=link}
{kind=link}